A double-edged bleeding edge: Classifying AI threats
Conversations about ‘AI threats’ typically collapse into one of two extremes. On the one hand, hype: unverified claims that don’t hold up to scrutiny and invite significant criticism. On the other, dismissal: it’s just old tradecraft with new branding.
As with most dichotomies like this, the truth is probably somewhere in between. Threat actors are using, and experimenting with, AI in different ways – both to facilitate attacks and as a target. It’s difficult – for various reasons – to get a handle on the true extent to which that’s happening, but as we noted in our coverage of attitudes towards AI on criminal forums, there has been a shift towards AI adoption in some tooling. Other research – such as ENISA’s 2025 Threat Landscape report – describes incremental, real-world usage of AI across the cybercrime ecosystem (including AI-generated phishing, voice cloning, deepfakes, scripting and AI-assisted reconnaissance), while noting, as we did in our research, that other malicious applications, such as AI-generated malware, remain for the moment in the realm of controlled demonstrations rather than active threats.
To help track and categorize AI threats, Sophos X-Ops has created a working taxonomy. It splits the problem into two top-level categories: Malicious use of AI, and Malicious targeting of AI. Each category contains multiple sub-categories of attacks, informed by incidents observed in the wild, our ongoing research into AI attacks, or attacks that we assess as realistic future possibilities.
This taxonomy is not intended to compete with other efforts in this sphere, such as MITRE ATLAS (an industry framework for adversarial AI), Microsoft’s taxonomy of failure modes in AI agents, MIT’s AI Risk Repository, or NIST AI 100-2. Instead, it’s designed to be a triage layer that sits above them. We’ll explore how our work can complement ATLAS in particular shortly. This taxonomy shouldn’t be considered a finished product; as with much in AI, it’s a work-in-progress, and this is a fast-moving space. But we believe this is an important contribution to other ongoing taxonomic efforts, and we’re committed to keeping it updated and relevant as new threats and categories emerge.
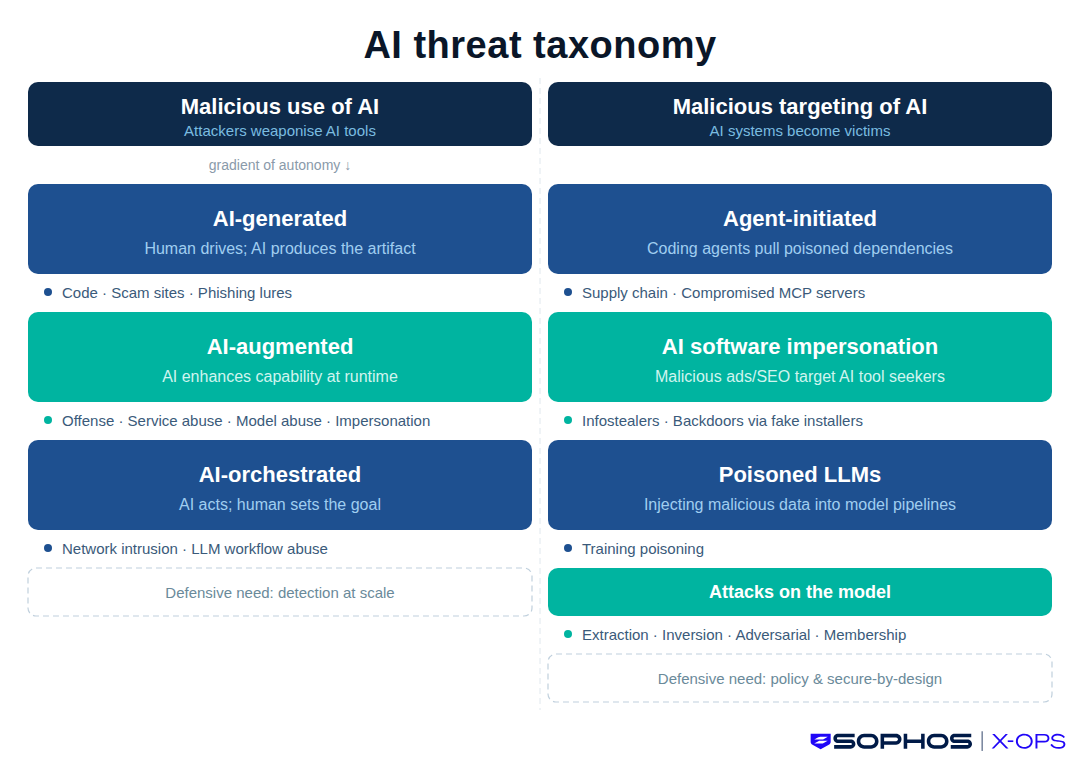
Figure 1: AI Threat taxonomy overview
Part one: Malicious use of AI
This is probably the category most people think of when they hear ‘AI threat’ – attackers abusing popular AI tools. But the threat is more nuanced than that; the level of AI involvement varies, and so does the appropriate defensive response.
A useful way to treat the sub-categories here is as a gradient of autonomy. AI-generated involves the human ‘driving,’ with AI as a tool in the passenger seat. AI-augmented means shared responsibility. In AI-orchestrated attacks, AI is driving and the human is a passenger setting the destination.
It’s worth noting here, as we’ve pointed out in some of our previous research on this topic, that all of these sub-categories – but particularly AI-orchestrated attacks – lower the capability floor. Threat actors with intent and opportunity but limited means can now access more advanced resources and skills ‘on tap,’ thereby expanding the population of viable threat actors at the lower end of the skill curve.
AI-generated
The lightest-touch use: generative AI produces an artifact – code, a fake website, a phishing lure – and a human takes over.
- AI-generated code: A threat actor uses a coding assistant, such as Cursor, to create scripts, exploits, payloads, and/or tools, which the human operator then deploys. As an example: between December 2025 and February 2026, a threat actor targeted multiple Mexican governmental organizations, using both Anthropic’s Claude Code and OpenAI’s GPT to generate scripts and tools. More recently, TTPs relating to The Gentlemen, a ransomware group, indicate usage of ChatGPT, Gemini, and Claude for development, and leaked chats from the group support this.
- AI-generated site: We published research on this back in 2023: scam websites and malicious portals spun up with the help of generative AI, achieving volume and polish while requiring little to no human effort.
- AI-generated lure: Social engineering scripts, pretexts, and lures drafted by an AI model and sent by a human.
Mitigations
Detections and protections still apply, because the delivered artifact is what matters. On the other hand, throughput, scale, and capability can increase significantly. Defenders should expect more campaigns, more variants, and faster iteration and adaptation.
AI-augmented
An AI model enhances a pre-existing capability, but at runtime.
- AI-augmented offensive support: A threat actor uses AI to support an attack – for example, using LLMs to improve the scale/depth of their reconnaissance and OSINT, or to automate vulnerability discovery and exploit development.
- AI-augmented service abuse: Malware that calls out to a commercial LLM API at runtime to dynamically generate attack commands, rather than embedding them statically in the binary. A prominent example in 2025 was LameHug, which CERT-UA attributed (with moderate confidence) to APT28: Python-based malware that queried Hugging Face’s hosting of Qwen2.5-Coder-32B-Instruct to produce Windows reconnaissance and data-theft commands on the fly, against Ukrainian government targets. The malware generated different commands per environment, making static analysis significantly less useful and outbound traffic to AI/ML APIs one of the few reliable detection surfaces.
- AI-augmented model abuse: Malware that ships with an embedded model that, for example, generates content (such as decoy documents and contextually-appropriate replies) or performs other malicious actions on an infected host. Note that, to our knowledge, this is a theoretical attack at the time of writing, and would be dependent on the size of the model. For instance, Mozilla’s llamafile allows for the distribution and running of an LLM within a single executable file. A pre-built version, with weights included, comes in at just under the 4GB Windows file-size execution limit (so still a relatively large file). Smaller models are available, of course, but may have restricted capabilities.
- AI-augmented impersonation: Voice cloning and face-swap tooling used in real-time fraud, executive impersonation, and KYC bypasses (as shown below in Figure 2).
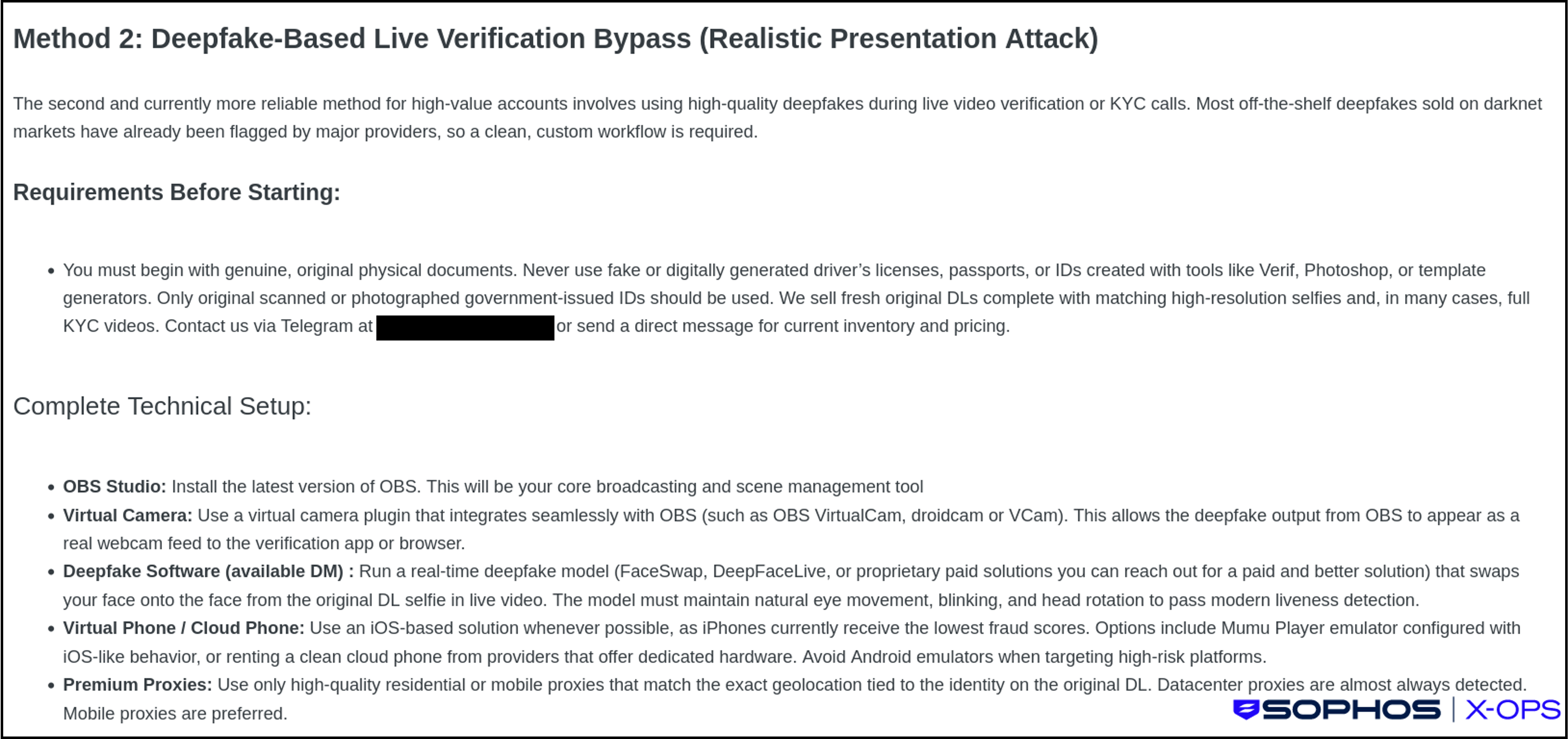
Figure 2: A threat actor on a criminal forum describes a set-up for using deepfakes to bypass KYC technologies
Mitigations
Attacks in this category are harder to catch with static analysis because the malicious behavior is dynamic and partly determined at runtime, by a model defenders can’t see. Calls to LLM-related API endpoints, characteristics of embedded models, sequencing and composition of command execution, and certain biological ‘tells’ relating to voice cloning and face-swaps may offer some detection opportunities.
AI-orchestrated
Here, AI performs the actions, with minimal human involvement but a degree of initiation/oversight.
- AI-orchestrated intrusion: An agent gains and/or escalates access through a network, using (for example) Model Context Protocol. A human operator sets a goal, and the agent executes the steps. Some aspects of the campaigns against multiple Mexican governmental organizations, mentioned earlier, fit into this subcategory. The fullest documented example to date is GTG-1002, the Chinese state-sponsored campaign Anthropic disclosed in November 2025: approximately thirty government and critical-infrastructure targets, with Claude Code running on a Kali Linux box that integrated open-source penetration-testing tools exposed as MCP servers. The AI scanned internet-facing services, exploited an SSRF vulnerability in a public web server, harvested SSH keys and cloud service-account tokens, and pivoted laterally across the victim’s cloud environment — making real-time tactical decisions about what to probe next while the human supplied strategic direction. In Anthropic’s June 2026 follow-up analysis, what distinguished GTG-1002 wasn’t technique count (roughly thirty MITRE ATT&CK techniques), but the orchestration layer wrapped around the model. In practice, orchestration may cover the full kill chain or only a portion of it: an operator might establish initial access manually and then hand off to an agent for post-exploitation, or stand up an agent that drives the operation end-to-end. The defensive implications are similar in either case.
- AI-orchestrated LLM abuse: A threat actor poisons or hijacks an LLM-powered workflow to deliver malicious content downstream to users
Mitigations
These attacks are still rare in the wild, but pose a significant amount of risk. They collapse the time between reconnaissance and action, and AI models don’t get tired or need breaks.
Part two: Malicious targeting of AI
The attacks in this category involve AI products, agents and ecosystems becoming victims (or unwitting accomplices), and succeed because of how AI systems are built and adopted.
Agent-initiated
- Agent-initiated compromise: A coding agent (such as Claude Code, Cursor, or Copilot-style tooling) pulls down a compromised NPM package or dependency, in the course of doing its job, or an MCP server used by an Agent is compromised to perform nefarious activity, like BCCing email to an unauthorized address. The agent itself isn’t malicious; it’s been pointed at a poisoned supply chain.
Mitigations
The novelty here isn’t supply chain attacks; those are a well-known threat. The threat lies in the fact that the agent compresses the time between ‘package published’ and ‘package executing in your environment’, with no human to pause and read the changelog, or check for risks associated with supply chain attacks. General mitigations here could include rate limiting, location management, and scope/permissions management.
AI software impersonation
- AI software impersonation: Malicious advertisements, sponsored results, SEO poisoning, or crafted shared LLM conversations take advantage of users searching for legitimate AI tools at unprecedented rates. The malware installed as a result may include infostealers, backdoors, and more.
Mitigations
This is a well-known attack, which we’ve been reporting on for some time – but with updated lures to take advantage of the demand for AI tools. There are two primary pillars of protection against this form of attack. One is detection of the eventual malware (and intermediate payloads), but the best (and earliest) form of defense is to only download applications and installers from confirmed legitimate vendor sites.
Poisoned LLMs
- LLM poisoning: A threat actor configures a custom model, or intentionally injects malicious or misleading data into a model’s training, fine-tuning, or retrieval pipeline to change how the model behaves. While we don’t yet have evidence of this attack occurring in the wild, researchers have demonstrated it theoretically, and attackers have previously weaponized ML models, albeit to deliver ‘traditional’ backdoors via ‘pickle’ files.
Mitigations
Be wary of links provided by AI models – verify that they’re pointing to legitimate domains, and be suspicious of any instruction to copy and paste content into a terminal or command window (particularly if the content is obfuscated).
Attacks on the model
Whereas the attacks described above target the AI ecosystem (installers, prompts, etc), this class of attack focuses on AI models themselves: weights, training data, and decision boundaries.
- Model extraction: Threat actors repeatedly query a deployed model until they can reconstruct an approximate copy via distillation – stealing the asset and undermining any moat (competitive advantage) built on training cost
- Training data inversion: Crafted queries extract training data from a deployed model – particularly concerning where training corpora include sensitive material, such as personal data, proprietary code, or copyrighted text
- Adversarial examples: Inputs engineered to trick a model into an erroneous classification, while seemingly benign (or obvious) to a human. Historically – and going back several years – these have included small adversarial changes to traffic signage, but the attacks may generalize to text, audio, and multimodal models
- Membership inference: Determining whether a specific record was part of a training set, by exploiting the model’s tendency to be more confident on data it has previously seen. This is an attack on privacy, and a concern for any organization that trains on customer data.
Mitigations
These are the techniques MITRE ATLAS covers most deeply, and the ones least likely to appear in standard telemetry; they often look like normal activity unless and until aggregate query patterns are measured over time.
How to use this taxonomy
As we noted earlier, there are also multiple other efforts in this field, with MITRE ATLAS perhaps being the most prominent shared vocabulary for AI threat intelligence. As of v5.10 (November 2025), it catalogs 16 tactics and 84 techniques modeled on the ATT&CK kill chain, with continued updated through 2026 adding agentic AI coverage.
However, ATLAS focuses on Malicious targeting of AI. That covers our Part Two, with our subcategories mapping on to ATLAS techniques like AI Supply Chain Compromise, LLM Prompt Injection, and Manipulate AI Model. But attacks using AI – covered in our Part One – sit at the edges of the ATLAS framework, rather than at its center.
This gap isn’t unique to ATLAS. Anthropic reached a similar conclusion at the broader ATT&CK level in its June 2026 LLM ATT&CK Navigator report: the autonomous, agentic behaviors that distinguish the most capable actors — kill chain orchestration, real-time pivot decisions, AI-directed execution — don’t yet have technique IDs in the framework. The vocabulary problem isn’t ours alone, and the relevant frameworks are likely to evolve.
The distinction between the two categories in our taxonomy is important, because they call for different defensive postures. Malicious use of AI is a productivity and volume problem; existing detection stacks may catch a lot, but the issue is the scale, and the speed at which campaigns iterate and adapt. On the other hand, Malicious targeting of AI is more of a trust and supply-chain concern, and it’s typically more appropriate to address it with policy, Secure-by-Design frameworks, and similar initiatives.
Moreover, treating them separately provides a clearer and more accurate picture of the threat. ‘AI-related incidents are up 300%’ is meaningless if that statistic conflates a GPT-authored phishing email with a coding agent that inadvertently introduced a backdoored dependency into production.
Ultimately, we suggest treating our taxonomy as a complementary addition to others, rather than a replacement. Ours can be used at intake, when defenders need a fast, unambiguous label for an ongoing incident, and then followed up with a more in-depth look at ATLAS for kill chain decomposition, mitigation mapping, and external sharing with partners and customers. Or, depending on the specifics of the incident, with information from Microsoft’s AI agent taxonomy, MIT’s Risk Repository, or NIST’s taxonomy on adversarial machine learning.
As we noted earlier, this taxonomy should not be considered complete. Every attempt has gaps, and AI is a particularly fast-moving space. New patterns and attack classes will surface (for example: autonomous reconnaissance; agent-on-agent attacks; model extraction at scale) and existing content may need to merge or be redefined.
But what matters is committing to the discipline of a taxonomy: when an incident comes in, label it specifically, distinguish who’s using what against whom, and let the data speak for itself.






