
10
March
2023
What
if
I
told
you…
that
you
could
run
a
website
from
behind
Cloudflare
and
only
have
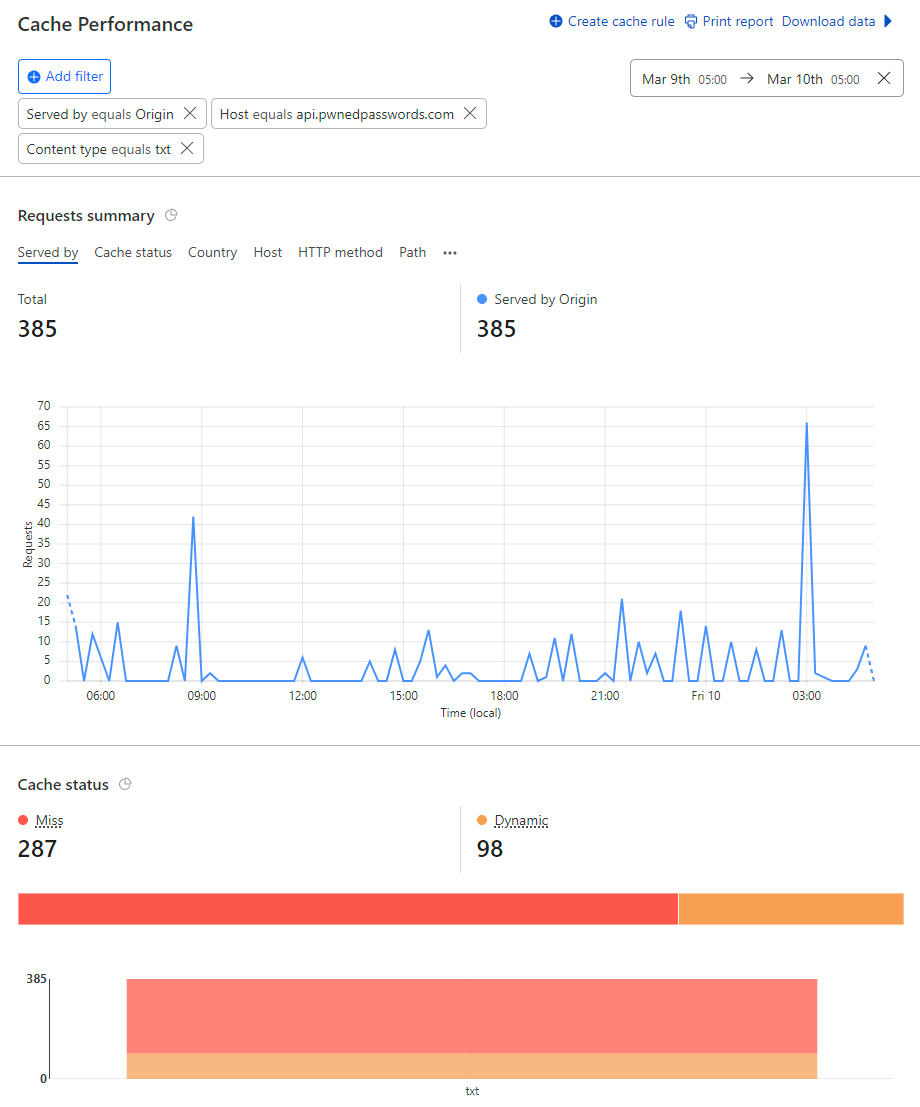
385
daily
requests
miss
their
cache
and
go
through
to
the
origin
service?
No
biggy,
unless…
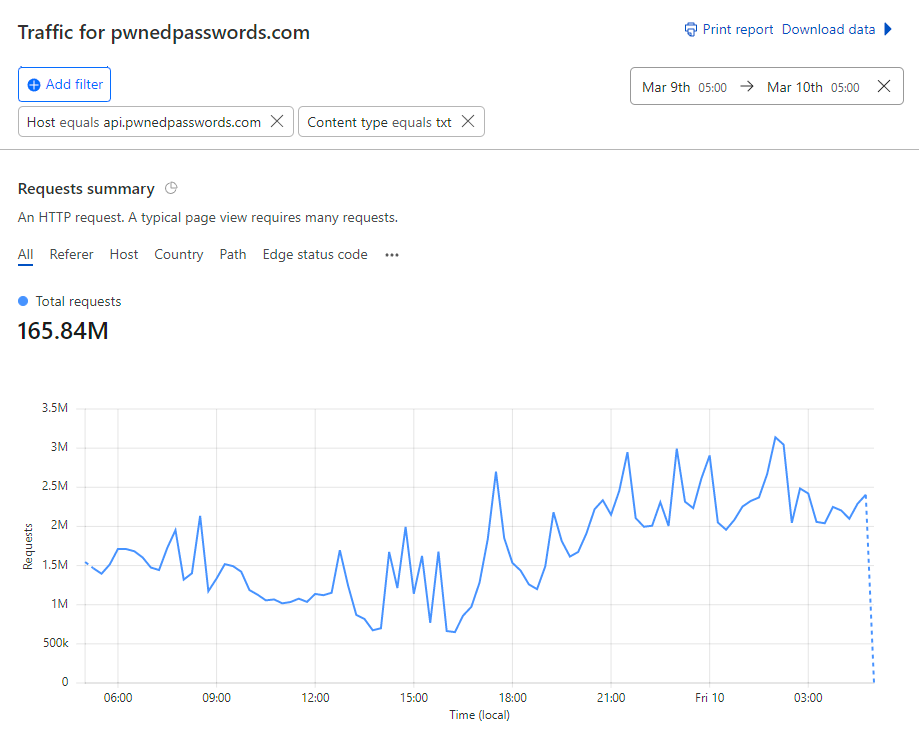
that
was
out
of
a
total
of
more
than
166M
requests
in
the
same
period:
Yep,
we
just
hit
“five
nines”
of
cache
hit
ratio
on
Pwned
Passwords
being
99.999%.
Actually,
it
was
99.9998%
but
we’re
at
the
point
now
where
that’s
just
splitting
hairs,
let’s
talk
about
how
we’ve
managed
to
only
have
two
requests
in
a
million
hit
the
origin,
beginning
with
a
bit
of
history:
Optimising
Caching
on
Pwned
Passwords
(with
Workers)-
@troyhunt
–
https://t.co/KjBtCwmhmT
pic.twitter.com/BSfJbWyxMy—
Cloudflare
(@Cloudflare)
August
9,
2018
Ah,
memories
😊
Back
then,
Pwned
Passwords
was
serving
way
fewer
requests
in
a
month
than
what
we
do
in
a
day
now
and
the
cache
hit
ratio
was
somewhere
around
92%.
Put
another
way,
instead
of
2
in
every
million
requests
hitting
the
origin
it
was
85k.
And
we
were
happy
with
that!
As
the
years
progressed,
the
traffic
grew
and
the
caching
model
was
optimised
so
our
stats
improved:
There
it
is
–
Pwned
Passwords
is
now
doing
north
of
2
*billion*
requests
a
month,
peaking
at
91.59M
in
a
day
with
a
cache-hit
ratio
of
99.52%.
All
free,
open
source
and
out
there
for
the
community
to
do
good
with
😊
pic.twitter.com/DSJOjb2CxZ—
Troy
Hunt
(@troyhunt)
May
24,
2022
And
that’s
pretty
much
where
we
levelled
out,
at
about
the
99-and-a-bit
percent
mark.
We
were
really
happy
with
that
as
it
was
now
only
5k
requests
per
million
hitting
the
origin.
There
was
bound
to
be
a
number
somewhere
around
that
mark
due
to
the
transient
nature
of
cache
and
eviction
criteria
inevitably
meaning
a
Cloudflare
edge
node
somewhere
would
need
to
reach
back
to
the
origin
website
and
pull
a
new
copy
of
the
data.
But
what
if
Cloudflare
never
had
to
do
that
unless
explicitly
instructed
to
do
so?
I
mean,
what
if
it
just
stayed
in
their
cache
unless
we
actually
changed
the
source
file
and
told
them
to
update
their
version?
Welcome
to
Cloudflare
Cache
Reserve:
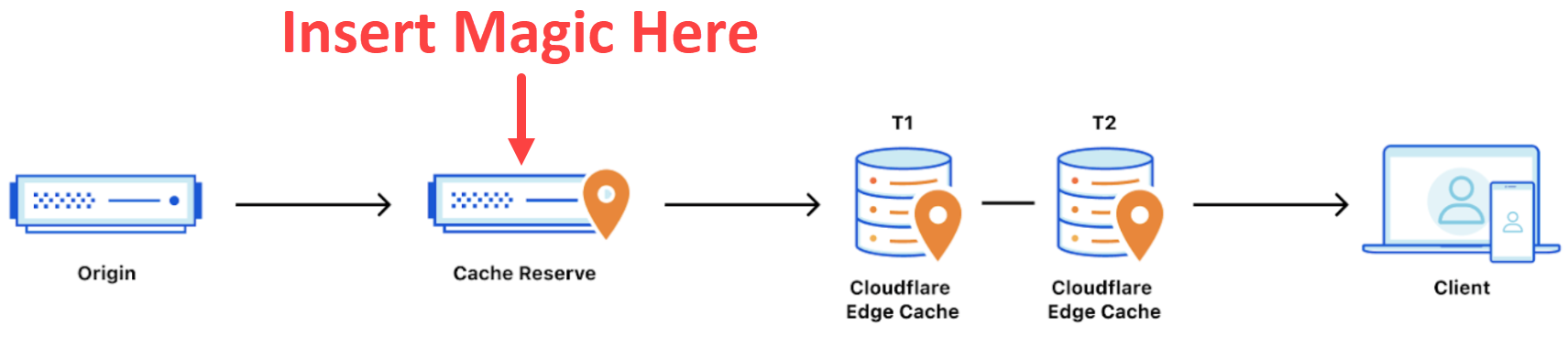
Ok,
so
I
may
have
annotated
the
important
bit
but
that’s
what
it
feels
like
–
magic
–
because
you
just
turn
it
on
and…
that’s
it.
You
still
serve
your
content
the
same
way,
you
still
need
the
appropriate
cache
headers
and
you
still
have
the
same
tiered
caching
as
before,
but
now
there’s
a
“cache
reserve”
sitting
between
that
and
your
origin.
It’s
backed
by
R2
which
is
their
persistent
data
store
and
you
can
keep
your
cached
things
there
for
as
long
as
you
want.
However,
per
the
earlier
link,
it’s
not
free:
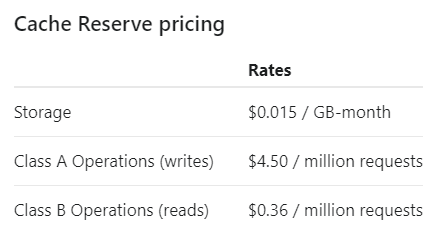
You
pay
based
on
how
much
you
store
for
how
long,
how
much
you
write
and
how
much
you
read.
Let’s
put
that
in
real
terms
and
just
as
a
brief
refresher
(longer
version
here),
remember
that
Pwned
Passwords
is
essentially
just
16^5
(just
over
1
million)
text
files
of
about
30kb
each
for
the
SHA-1
hashes
and
a
similar
number
for
the
NTLM
ones
(albeit
slight
smaller
file
sizes).
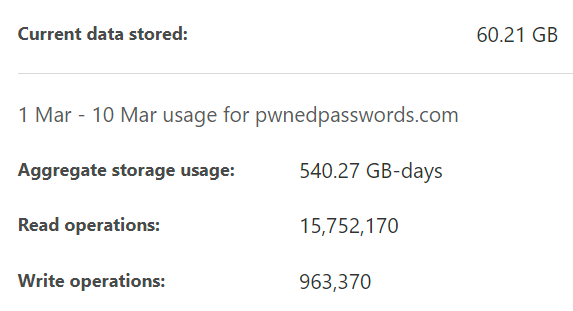
Here
are
the
Cache
Reserve
usage
stats
for
the
last
9
days:
We
can
now
do
some
pretty
simple
maths
with
that
and
working
on
the
assumption
of
9
days,
here’s
what
we
get:
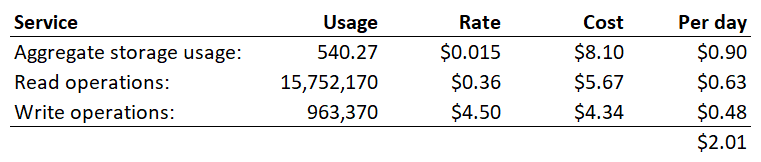
2
bucks
a
day
😲
But
this
has
taken
nearly
16M
requests
off
my
origin
service
over
this
period
of
time
so
I
haven’t
paid
for
the
Azure
Function
execution
(which
is
cheap)
nor
the
egress
bandwidth
(which
is
not
cheap).
But
why
are
there
only
16M
read
operations
over
9
days
when
earlier
we
saw
167M
requests
to
the
API
in
a
single
day?
Because
if
you
scroll
back
up
to
the
“insert
magic
here”
diagram,
Cache
Reserve
is
only
a
fallback
position
and
most
requests
(i.e.
99.52%
of
them)
are
still
served
from
the
edge
caches.
Note
also
that
there
are
nearly
1M
write
operations
and
there
are
2
reasons
for
this:
-
Cache
Reserve
is
being
seeded
with
source
data
as
requests
come
in
and
miss
the
edge
cache.
This
means
that
our
cache
hit
ratio
is
going
to
get
much,
much
better
yet
as
not
even
half
all
the
potentially
cacheable
API
queries
are
in
Cache
Reserve.
It
also
means
that
the
48c
per
day
cost
is
going
to
come
way
down
🙂 -
Every
time
the
FBI
feeds
new
passwords
into
the
service,
the
impacted
file
is
purged
from
cache.
This
means
that
there
will
always
be
write
operations
and,
of
course,
read
operations
as
the
data
flows
to
the
edge
cache
and
makes
corresponding
hits
to
the
origin
service.
The
prevalence
of
all
this
depends
on
how
much
data
the
feds
feed
in,
but
it’ll
never
get
to
zero
whilst
they’re
seeding
new
passwords.
An
untold
number
of
businesses
rely
on
Pwned
Passwords
as
an
integral
part
of
their
registration,
login
and
password
reset
flows.
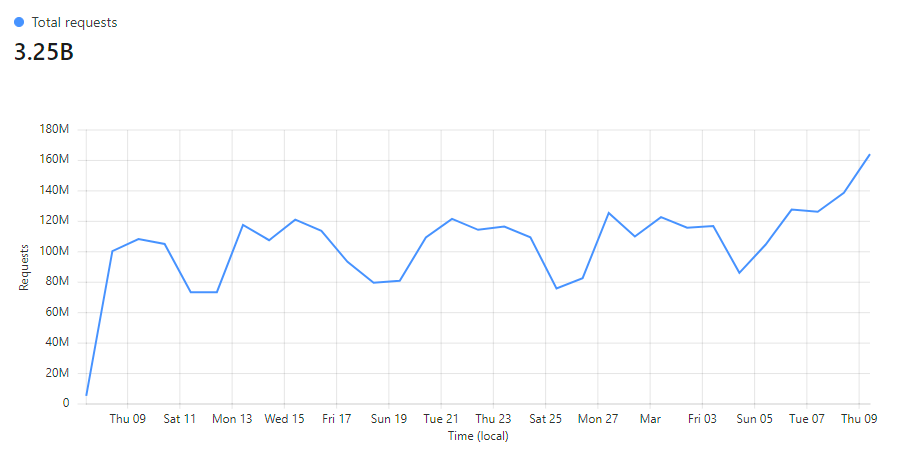
Seriously,
the
number
is
“untold”
because
we
have
no
idea
who’s
actually
using
it,
we
just
know
the
service
got
hit
three
and
a
quarter
billion
times
in
the
last
30
days:
Giving
consumers
of
the
service
confidence
that
not
only
is
it
highly
resilient,
but
also
massively
fast
is
essential
to
adoption.
In
turn,
more
adoption
helps
drive
better
password
practices,
less
account
takeovers
and
more
smiles
all
round
😊
As
those
remaining
hash
prefixes
populate
Cache
Reserve,
keep
an
eye
on
the
“cf-cache-status”
response
header.
If
you
ever
see
a
value
of
“MISS”
then
congratulations,
you’re
literally
one
in
a
million!
Full
disclosure:
Cloudflare
provides
services
to
HIBP
for
free
and
they
helped
in
getting
Cache
Reserve
up
and
running.
However,
they
had
no
idea
I
was
writing
this
blog
post
and
reading
it
live
in
its
entirety
is
the
first
anyone
there
has
seen
it.
Surprise!
👋
Have
I
Been
Pwned
Pwned
Passwords
Cloudflare








