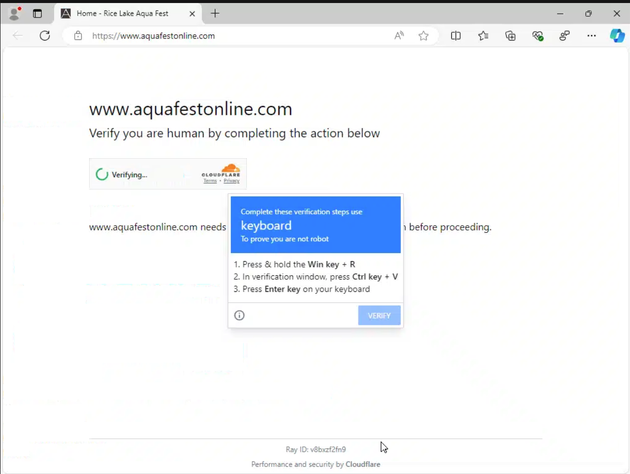
Cloudflare provides an easier method to thwart AI bots
“The widespread use of generative AI has led to a surge in the need for data used for model training or inference, and despite some AI firms clearly labeling their web scraping bots, not all are being forthright,” stated individuals from Clou

“The widespread use of generative AI has led to a surge in the need for data used for model training or inference, and despite some AI firms clearly labeling their web scraping bots, not all are being forthright,” stated individuals from Cloudflare in a blog entry.
As per the blog post’s writers, “Allegedly, Google paid $60 million annually to obtain a license for user-generated content from Reddit, Scarlett Johansson claimed that OpenAI utilized her voice for their new virtual assistant without her permission, and most recently, Perplexity has faced accusations of posing as authentic visitors in order to extract content from websites. The significance of genuine content in large quantities has never been greater.”
Last year, Cloudflare unveiled a feature that enables any of its users, irrespective of their plan, to prevent specific categories of bots, including select AI crawlers. According to Cloudflare, these bots adhere to instructions in websites’ robots.txt files, abstain from using unauthorized content to train their models, and refrain from collecting data for retrieval-augmented generation (RAG) applications.

: The Future of MCP Authentication")