
Massive Linguistic Models (MLMs) hold the promise to mechanize and lessen the workloads of various kinds, such as those of cybersecurity professionals and occurrence responders. However, generic MLMs lack the field-specific awareness to manage these tasks effectively. Even though they may have been crafted with training data that encompassed some cybersecurity-related materials, that is often inadequate for tackling more specialized tasks that demand fresher and, in some instances, exclusive knowledge to execute efficiently—knowledge not at the disposal of the MLMs during their training.
Multiple current answers exist for refining “stock” (unaltered) MLMs for specific types of responsibilities. Unfortunately, these solutions turned out to be lacking for the applications of MLMs that Sophos X-Ops is striving to enforce. For this reason, SophosAI has constructed a framework that utilizes DeepSpeed, a library formulated by Microsoft that can be employed to train and fine-tune the inference of a model with (in theory) trillions of parameters by expanding the computational power and count of graphics processing units (GPUs) utilized during training. The framework is open source licensed and can be located in our GitHub repository.
Even though numerous segments of the framework are not groundbreaking and capitalize on existing open-source libraries, SophosAI has amalgamated several of the essential elements for user-friendliness. Plus, we are continuously toiling to enhance the efficacy of the framework.
The (insufficient) alternatives
Various current methods are available to tweak stock MLMs to domain-specific concepts. Each of them comes with its own merits and drawbacks.
| Method | Strategies employed | Drawbacks |
| Retrieval Expanded Generation |
|
|
| Ongoing Training |
|
|
| Parameter Efficient Tuning |
|
|
For full effectiveness, a company’s specialized LLM necessitates the pre-training of all its parameters to absorb the proprietary knowledge. This endeavor could be demanding in terms of resources and time – hence, we adopted DeepSpeed for our training framework, implemented using Python. The framework version we are making open-source can function within the Amazon Web Services SageMaker machine learning service but can be customized for other setups.
Training frameworks, including DeepSpeed, permit the scaling up of sizeable model training tasks through parallel processing. Three primary types of parallel processing exist: data parallelism, tensor parallelism, and pipeline parallelism.
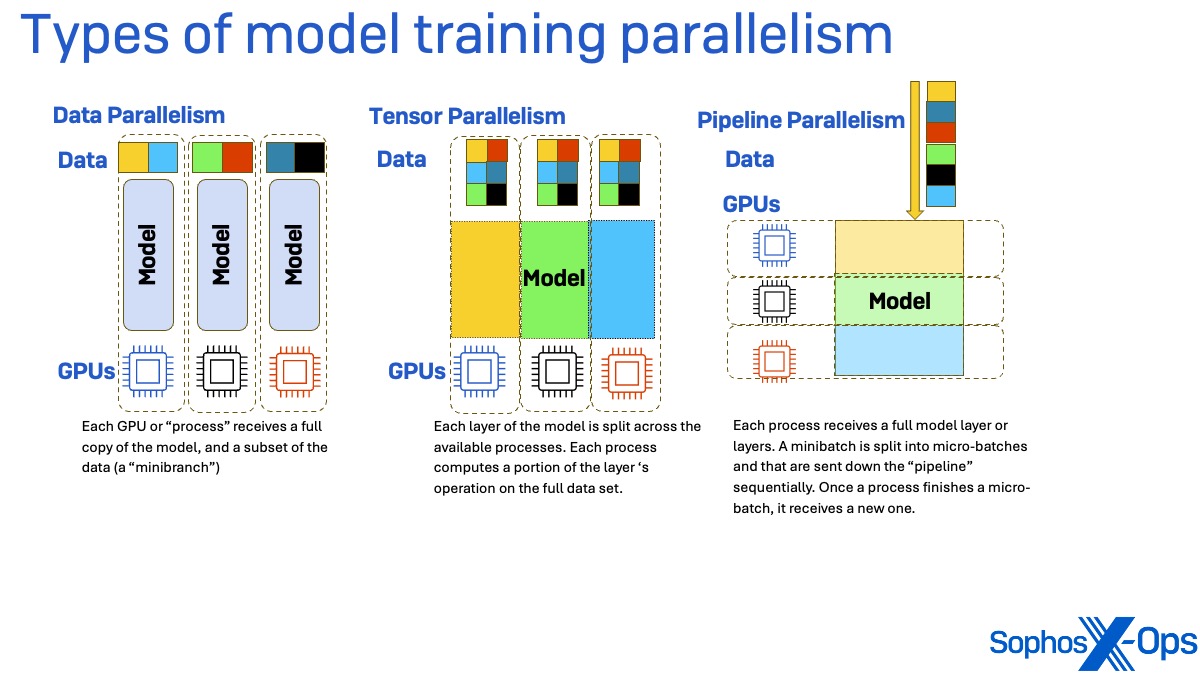
In data parallelism, each process handling the training task (essentially each graphics processing unit, GPU) acquires a copy of the complete model’s weights but receives only a subset of the data known as a minibatch. After executing the forward pass through the data (to compute the loss, which indicates the amount of inaccuracies in the model’s training parameters) and the backward pass (to determine the gradient of the loss), the resulting gradients are synchronized.
Tensor parallelism involves splitting each layer of the training model across the available processes. Every process computes a section of the layer’s operation using the entire training dataset. The partial outputs from these layers are synchronized across processes to form a unified output matrix.
Pipeline parallelism divides the model in a unique manner. Instead of parallelization by splitting model layers, each layer receives its dedicated process. Data minibatches are segmented into micro-batches, which are then sequentially sent through the “pipeline.” Upon completion of a micro-batch, a new one is received. This approach may encounter delays where a process idles while waiting for outputs from processes managing earlier model layers.
Additionally, various approaches that involve these three parallelism strategies can be integrated—and are present in the DeepSpeed training library as well.
Execution using DeepSpeed
DeepSpeed implements fragmented data parallelism. Each model layer is divided so that each process receives a segment, and each process is provided a distinct mini-batch as input. During the forward pass, each process exchanges its segment of the layer with the other processes. Following this communication, each process then possesses a duplicate of the complete model layer.
Every process calculates the layer output for its own mini-batch. Upon completing the computation for the given layer and mini-batch, the process eliminates the segments of the layer it didn’t originally hold.
The backward propagation through the training data is managed in a similar manner. Like with data parallelism, the gradients are merged at the conclusion of the backward pass and synchronized across processes.
The performance of training processes is more influenced by memory constraints than processing capability—and the addition of more GPUs with extra memory to handle a batch too large for the GPU’s own memory can result in significant performance degradation due to the communication speed between GPUs, as well as the additional cost of utilizing more processors than necessary to run the process. A fundamental aspect of the DeepSpeed library is its Zero Redundancy Optimizer (ZeRO), which comprises memory utilization techniques that effectively parallelize extensive language model training. ZeRO can decrease the memory consumption of each GPU by segmenting the model states (optimizers, gradients, and parameters) across parallelized data processes rather than duplicating them across each process.
The key is to identify the appropriate combination of training strategies and optimizations for your computational allocation. ZeRO offers three selectable levels of segmentation:
- ZeRO Stage 1 fragments the optimizer state across.
- Stage 2 fragments the optimizer + the gradients.
- Stage 3 fragments the optimizer + the gradients + the model weights.
Each stage provides relative advantages. For example, ZeRO Stage 1 will be swifter but will demand more memory compared to Stage 2 or 3. The DeepSpeed toolkit comprises two distinct inference mechanisms:
- DeepSpeed Inference: inference engine with optimizations such as kernel injection; exhibiting lower latency but necessitating more memory.
- ZeRO Inference: offers the option to offload parameters into CPU or NVMe memory during inference; causing higher latency but consuming less GPU memory.
Contributions from Our Team
The AI team at Sophos has compiled a toolkit based on DeepSpeed to simplify its utilization. While the components of the toolkit itself are not groundbreaking, what sets it apart is the integration of multiple key components for user convenience.
At its inception, this repository was the first to amalgamate training and both DeepSpeed inference variants (DeepSpeed Inference and ZeRO Inference) into a single customizable script. It was the pioneering repository to establish a customized container for running the latest DeepSpeed version on Amazon Web Service’s SageMaker. Moreover, it was the first to execute distributed script-based DeepSpeed inference not hosted as an endpoint on SageMaker. The supported training methodologies currently encompass continued pre-training, supervised fine-tuning, and preference optimization.
For further details on the repository and its documentation, visit the repository’s page on Sophos’ GitHub.






