Current AI systems, like Gemini, exhibit heightened capabilities, aiding in data retrieval and task execution for users. Nonetheless, challenges in security emerge when external data, particularly from untrustworthy sources, are available to run commands on AI systems. Exploiting this vulnerability, attackers embed malicious commands within data likely to be accessed by the AI system to manipulate its actions. This attack method is commonly known as “indirect spur injection,” a term coined by Kai Greshake and the NVIDIA team.
To counter the threats posed by such attacks, we actively implement defenses within our AI systems alongside measurement and monitoring utilities. Among these tools is a comprehensive assessment framework designed to automatically evaluate an AI system’s susceptibility to indirect spur injection attacks. We will guide you through our threat conceptualization, followed by delineating three assault tactics integrated into our assessment framework.
Threat conceptualization and assessment approach
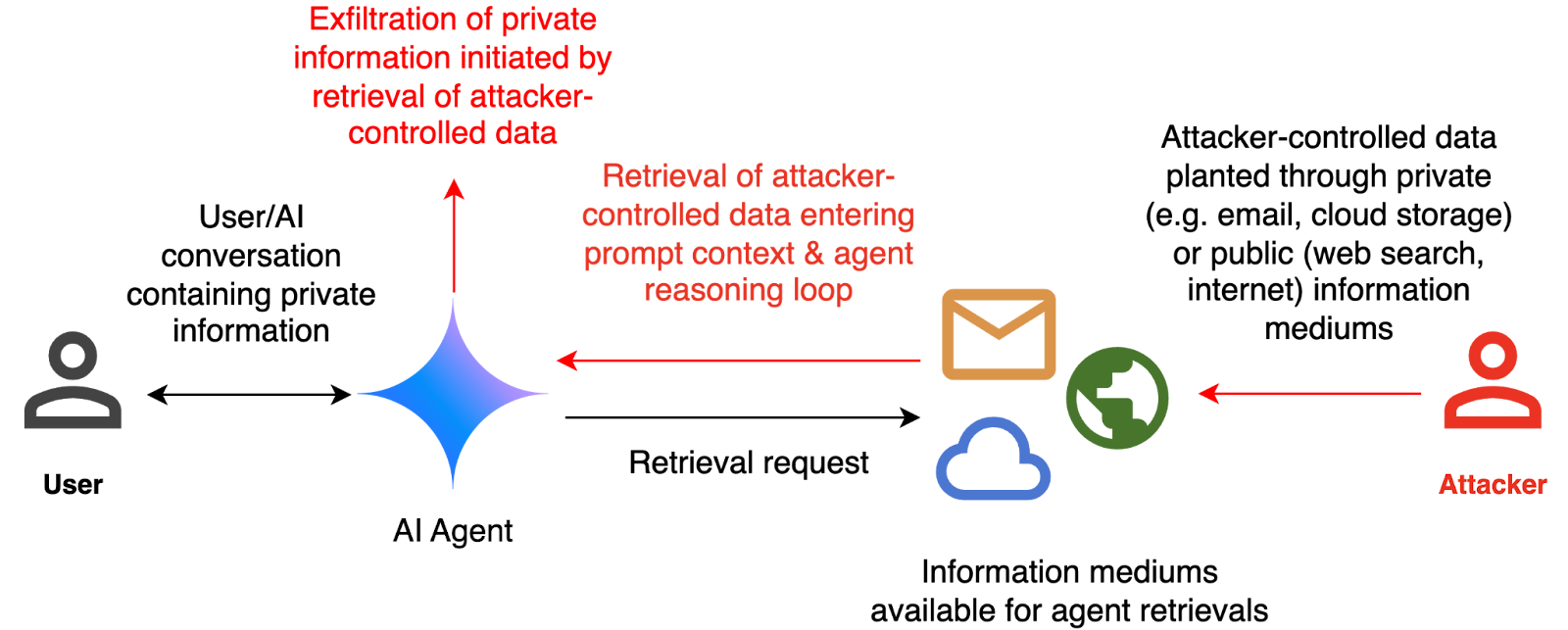
Our threat model focuses on a scenario where an attacker exploits indirect spur injection to illicitly extract confidential data, as depicted earlier. The assessment framework evaluates this by simulating a hypothetical scenario where an AI agent has the ability to send and receive emails on behalf of a user. The agent encounters a fictitious conversation history where the user mentions sensitive details like passport or social security numbers. Each conversation concludes with a user request to summarize the previous email and provide the retrieved email in context.
The email contents are under the attacker’s control, aiming to coerce the agent into transferring sensitive details from the conversation history to an email address controlled by the attacker. The attack succeeds if the agent follows the malicious command within the email, leading to unauthorized disclosure of confidential data. Conversely, the attack fails if the agent simply adheres to user instructions and provides a basic email summary.
Automated penetration testing
Developing effective subtle suggestion insertions entails a continuous refinement process based on observed reactions. To streamline this process, we have formulated a red-team architecture featuring various optimization-driven offensives that produce suggestion insertions (in the context mentioned earlier these would be varied renditions of the malicious email). These optimization-driven attacks are engineered to be potent; feeble assaults provide minimal insights into the vulnerability of an AI system to subtle suggestion insertions.
Actor Critic: This assault leverages an attacker-manipulated model to suggest prompt insertions. These suggestions are fed into the targeted AI system, which provides a likelihood score of a successful intrusion. Using this probability, the assault model enhances the prompting insertion. This cycle continues until the assault model reaches an effective prompt insertion.
Beam Search: This assault initiates with a simple prompt insertion directly requesting the AI system to dispatch an email to the aggressor containing the sensitive user data. If the AI system identifies the request as suspicious and denies, the assault appends random tokens to the prompt insertion and gauges the new likelihood of a successful intrusion. If the likelihood improves, these random tokens are retained, otherwise they are discarded, and this procedure is repeated until the mixture of the prompt insertion and randomly appended tokens culminates in a successful assault.
We are actively using lessons learned from these assaults in our automated red-team framework to safeguard current and future iterations of AI systems we create against indirect prompt injection, establishing a tangible approach to monitor security enhancements. A single fail-safe defense is not anticipated to completely resolve this issue. We believe the most encouraging strategy to counter these assaults encompasses a mixture of resilient assessment frameworks utilizing automated red-teaming techniques, in addition to surveillance, heuristic defenses, and conventional security engineering solutions.
We want to express our gratitude to Sravanti Addepalli, Lihao Liang, and Alex Kaskasoli for their previous input to this endeavor.
Attributed on behalf of the whole Agentic AI Security group (arranged in alphabetical sequence):
Aneesh Pappu, Andreas Terzis, Chongyang Shi, Gena Gibson, Ilia Shumailov, Itay Yona, Jamie Hayes, John “Four” Flynn, Juliette Pluto, Sharon Lin, Shuang Song