Given the rapid growth and adoption of AI in various industries, malicious actors are increasingly targeting these systems with higher frequency and sophistication. Numerous cybersecurity leaders acknowledge the criticality and immediacy of AI security but lack established procedures to adequately address and mitigate emerging AI risks throughout the extensive adversarial AI threat landscape.
Robust Intelligence (now part of Cisco) and the UK AI Security Institute collaborated with the National Institute of Standards and Technology (NIST) to unveil the most recent update to the Adversarial Machine Learning Taxonomy. This joint effort aimed to address the need for a comprehensive adversarial AI threat landscape while promoting alignment across regions to standardize the approach for understanding and mitigating adversarial AI.
The results of a survey highlighted in the Global Cybersecurity Outlook 2025 report by the World Economic Forum underscore the disparity between AI adoption and readiness: “While 66% of organizations expect AI to have the most significant impact on cybersecurity in the upcoming year, only 37% claim to have established processes to evaluate the security of AI tools before implementation.”
Effectively tackling these attacks necessitates that AI and cybersecurity communities remain well-informed about the prevailing AI security challenges. To address this requirement, we have collaborated on the 2025 update to NIST’s taxonomy and terminology of adversarial machine learning.
Let’s delve into the latest update to the publication, explore the attack and mitigation taxonomies at a high level, and briefly ponder the significance and utility of taxonomies.
What’s Fresh in the Update?
The previous rendition of the NIST Adversarial Machine Learning Taxonomy focused on predictive AI, which involves models designed to make accurate predictions based on historical data patterns. Various adversarial techniques were categorized into three main attacker objectives: availability breakdown, integrity breaches, and privacy breaches. It also contained an initial AI attacker technique landscape for generative AI, models that generate new content based on existing data. Generative AI incorporated all three adversarial technique classifications and introduced misuse breaches as an additional category.
In this recent taxonomy update, we elaborate on the generative AI adversarial techniques and breaches section while ensuring the predictive AI segment remains pertinent and precise in today’s adversarial AI environment. One significant enhancement in the latest version is the inclusion of an index of techniques and violations at the onset of the document. This not only enhances navigability but also facilitates referencing techniques and violations mentioned in external sources, making the taxonomy a more practical resource for AI security practitioners.
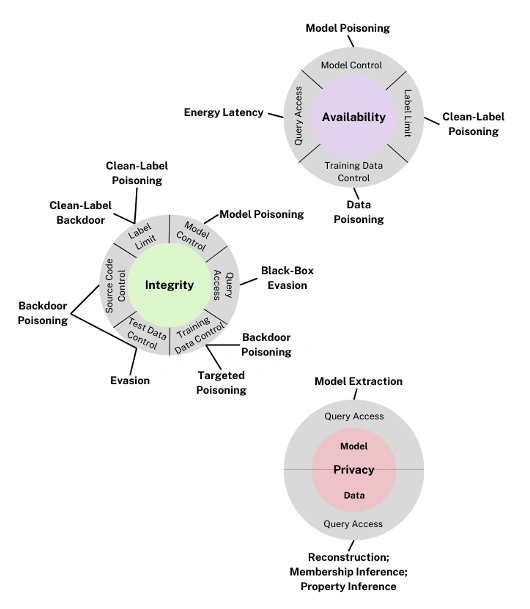
Unpacking Offensives Targeting Predictive AI Models
The three consistent attacker objectives across predictive and generative AI sections are:
- Availability breakdown: These attacks impair the performance and availability of a model for its users.
- Integrity breaches: They seek to compromise model integrity and produce inaccurate outputs.
- Privacy breaches: This involves the inadvertent leakage of confidential or proprietary information, such as details about the model’s foundation and training data.
Categorizing Assaults on Generative AI Models
The generative AI taxonomy upholds the same three attacker objectives as predictive AI—availability, integrity, and privacy—and encompasses additional distinct techniques. Unique to generative AI is a fourth attacker objective: misuse breaches. The updated taxonomy version broadened the coverage of generative AI adversarial techniques to reflect the most current landscape of attacker methods.
Misuse breaches: These repurpose generative AI capabilities to advance an adversary’s malevolent goals by generating harmful content to support cyberattack endeavors.
The damages associated with misuse violations aim to yield outputs that could be detrimental to others. For instance, malevolent actors could resort to direct prompt assaults to evade model defenses and produce perilous or unwanted output.
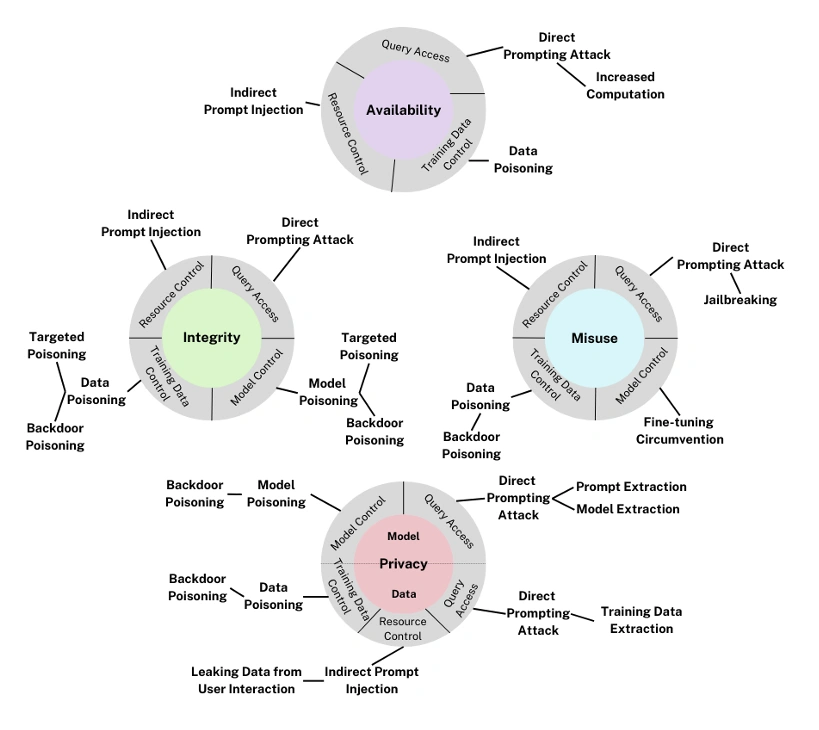
Adversaries can leverage a variety of techniques to achieve one or multiple objectives. The elaboration of the generative AI section shines a light on attacker methods specific to generative AI, like direct prompt injection, data extraction, and indirect prompt injection. Moreover, a fresh set of supply chain attacks surfaces. Supply chain attacks, not tailored to a specific model violation, are omitted from the previously referenced taxonomy diagram.
Supply chain attacks: These are rooted in the intricate and inherited risks within the AI supply chain. Each component—be it open-source models or third-party data—can introduce security vulnerabilities into the entire system.
Adopting supply chain assurance measures such as vulnerability scans and dataset validations can mitigate these risks.
Direct prompt injection: This modifies a model’s behavior through direct input from an adversary. It can serve to create intentionally malicious content or extract sensitive data.
To enhance security, consider training for alignment and deploying a real-time prompt injection detection solution.
Indirect prompt injection: This method involves delivering adversarial inputs through a third-party channel. Such a technique can further numerous objectives, including information manipulation, data extraction, unauthorized disclosures, fraud, malware dissemination, and more.
Suggested mitigation approaches to minimize risks include reinforcement learning via human feedback, input filtering, and the utilization of an LLM moderator or interpretability-based solution.
What Aims do Taxonomies Serve, Ultimately?
Hyrum Anderson, Co-author and Director of AI & Security at Cisco, rightly emphasizes that “taxonomies play a vital role in organizing our comprehension of attack techniques, capabilities, and objectives. They also have a lasting impact on enhancing communication and collaboration in a swiftly evolving domain.”
Hence, Cisco is committed to supporting the development and continuous enhancement of shared standards by collaborating with prominent bodies like NIST and the UK AI Security Institute.
These resources furnish us with enhanced mental constructs for categorizing and deliberating on new techniques and capabilities. Recognizing and educating about these vulnerabilities aid in fortifying AI systems and formulating informed standards and policies.
For a detailed examination of the NIST Adversarial Machine Learning Taxonomy and an extensive glossary of crucial terms, refer to the complete paper.
We welcome your feedback. Feel free to Ask a Question, Comment Below, and stay connected with Cisco Secure on social media!
Cisco Security Social Channels
Instagram
Facebook
Twitter
LinkedIn